


Apache HBase: RegionServers co-location

Feb 22, 2022
Never miss our publications about Open Source, big data and distributed systems, low frequency of one email every two months.
RegionServers are the processes that manage the storage and retrieval of data in Apache HBase, the non-relational column-oriented database in Apache Hadoop. It is through their daemons that any CRUD (for Create, Read, Update and Delete) query is performed. Together with the Master, they are the guarantors of data backup and performance optimization. In production environments, a single RegionServer is deployed on each compute node, allowing for scaling of both workloads and storage sharing by adding additional nodes.
Today, many companies still choose to run their infrastructure on-premises, i.e., in the company’s own data centers, as opposed to in the cloud. Their bare metal server deployments take advantage of the full memory space of each machine. Among them, those whose workloads are mostly based on Apache HBase do not always use all their resources. This is because the amount of RAM a RegionServer can consume is capped by the Java JVM. If each RegionServer could take advantage of all of the RAM it has available, its performance would potentially be greatly enhanced. In this case, the removal of nodes from the cluster could be considered, thus reducing the licensing costs that depend directly on it, and better use the available resources. Therefore, on an on-premises infrastructure, can we allow each RegionServer to exploit more memory resources, in order to support the workload due to the removal of one or more Workers?
RegionServers co-location
On Apache Ambari, the size of the memory space allocated to the JVM of each RegionServer can be chosen: from 3 to 64 GB. However, the documentation advises not to exceed 30 GB. Indeed, beyond this threshold, the Garbage Collector, whose mission is to clean the data that are no longer used in RAM, is overloaded: this results in pauses in the middle of a workload, making it unavailable for several seconds. A possible solution would be to multiply the number of RegionServers per machine, in order to keep 30 GB JVMs, while taking advantage of the available RAM.
A project on Github describes the procedure to launch several RegionServers on a same host, on an HDP distribution managed by Ambari. It is a script mainly composed of a for loop that runs the classic RegionServer startup steps, as many times as you want. For each new instance, the initial configuration file will be copied and the port numbers will be incremented. The log and PID folders of each RegionServer will be created automatically.
This script must be placed in the HBase configuration directory, on each of the Workers on which we want to multiply the RegionServers, and then be launched by Ambari. Here are the few manual steps needed to set up this script.
#!/bin/bash
# Change the name of the file `hbase-daemon.sh` to `hbase-daemon-per-instance.sh`
mv /usr/hdp/current/hbase-regionserver/bin/hbase-daemon.sh /usr/hdp/current/hbase-regionserver/bin/hbase-daemon-per-instance.sh
# Copy from this project the `hbase-daemon.sh` file
cp ./hbase-daemon.sh /usr/hdp/current/hbase-regionserver/bin/hbase-daemon.sh
# Gives the administrator read, write and execute rights on the copied file
chmod +rwx /usr/hdp/current/hbase-regionserver/bin/hbase-daemon.sh
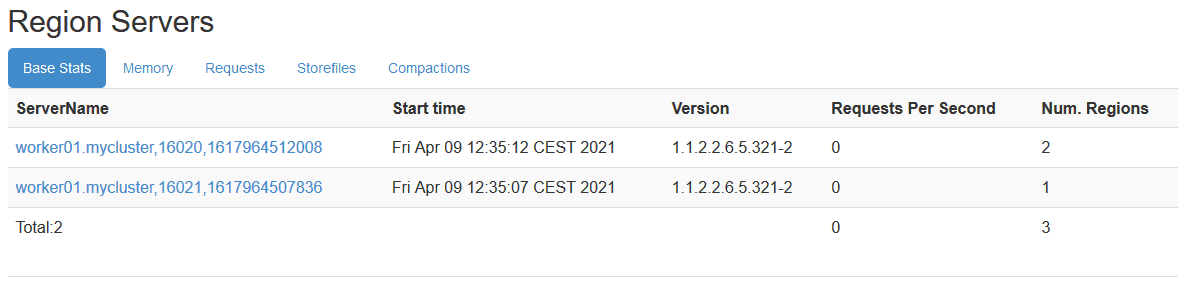
Although these new instances are not visible in Ambari, they are nevertheless visible on the HBase Master UI. After having done each of these steps, you just have to start each RegionServer via the Ambari interface. Indeed, when an action will be performed on a RegionServer via the Ambari interface, it will also be launched on each RegionServer of the same host. For example, if a restart of the RegionServers of the host worker01 is done via Ambari, all the new RegionServer instances of the host worker01 will also launch a restart.
Test environment and methodology
To measure the performance impact of these new RegionServers instances, the use of a YCSB test suite is relevant. YCSB (for Yahoo! Cloud Serving Benchmark) is a suite of open source programs used to evaluate the recovery and maintenance capabilities of computer programs. It is often used to compare the relative performance of NoSQL database management systems, such as HBase. This test suite replicates the following steps in each iteration:
- Creation (or re-creation) of a 50 regions table
- Insertions with new entries (~150 GB)
- YCSB workload A, “Update heavy”: this workload is composed of 50/50 reads and writes. Updates are done without reading the element first. An example of application would be the cookies of a session on a web site.
- YCSB workload F, ” Read-modify-write ”: for this workload, each element will be read, modified and then rewritten. An example of an application would be a database where the records of a user are read and modified by the user.
For each workload, the execution time (in seconds) and the operation rate (in operations/second) will be recovered. These tests were performed on an HDP 2.6.5 cluster, on 4 bare-metal Workers with 180 GB of RAM and 4 disks of 3 TB each, with an inter-machine bandwidth of 10 GB/s. All the RegionServers of these 4 Workers formed a “Region Server Group”, and were therefore exclusively used for the test set, and for no other workload. In each situation, the test set was launched at least three times.
Adding new instances
This first step consists of removing a node from the cluster and then adding RegionServers on different hosts to measure performance. The following table shows the results: ‘w1’ stands for ‘Worker 1’ and the sticks represent the number of RegionServers on each host. Finally the indication “w̶1̶” indicates that the “Worker 1” node was removed from the HBase cluster for the given test. The results shown are averages calculated over all test batteries.
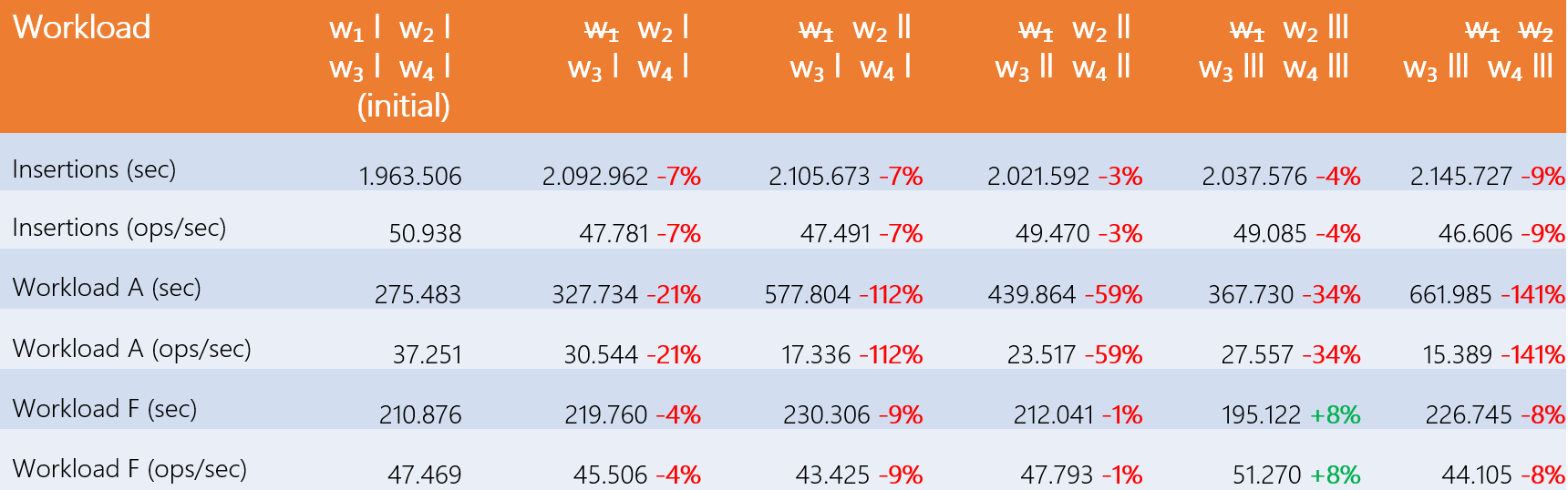
We notice that adding one or more RegionServers on each host does not compensate for the loss of a machine. Moreover, an imbalance of RegionServers from one host to another causes performance to plummet. This is because the Master sees each RegionServers independently, as if they each had their own machine. Thus, the regions (data plots) are evenly distributed across each RegionServers. A host with more RegionServers than another will have to process more regions: the workload is then less evenly distributed between the machines. Since a RegionServer does not compensate for the loss of a machine, this proves the existence of a bottleneck at some stage of the data flow.
Configuration optimization
This study consists in modifying properties on Ambari in order to obtain better performances of our new RegionServers. The properties in question are the following:
- DataNodes:
- Maximum number of threads (
dfs.datanode.max.transfer.threads) - RAM allocated to DataNodes (
dtnode_heapsize)
- Maximum number of threads (
- RegionServers:
- Number of handlers (
hbase.regionserver.handler.count) - RAM allocated to RegionServers (
hbase_regionserver_heapsize)
- Number of handlers (
The following table shows the performance obtained initially, then with 2 RegionServers per Worker, then with the most effective configuration.
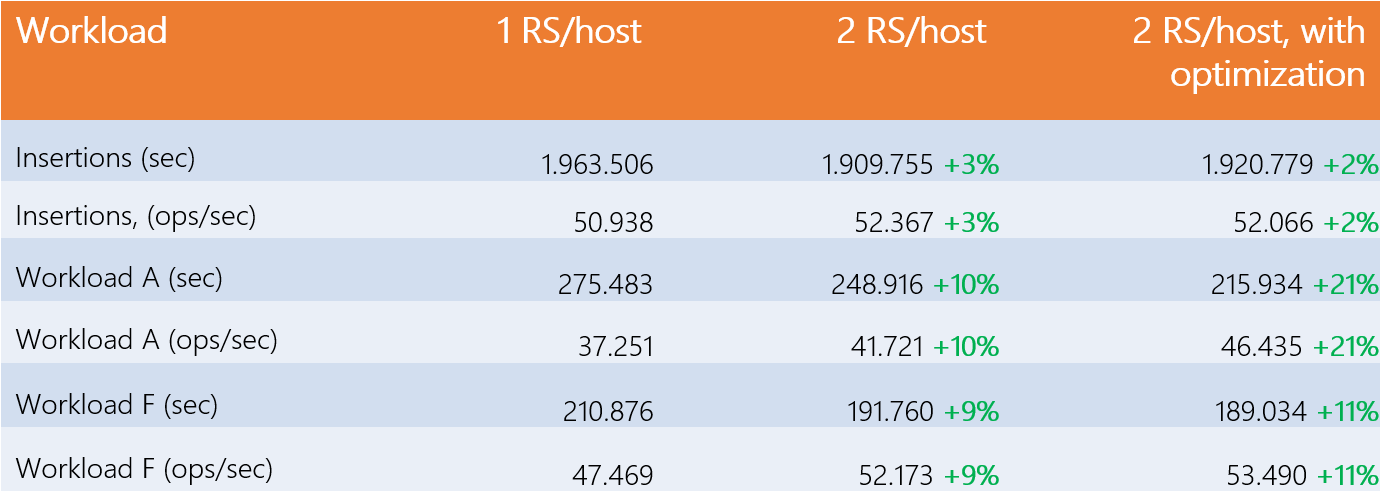
As can be seen, the gains from adding a RegionServer on each Worker are 10%: they are therefore negligible, and explain the results of the first study, amplified by the consideration of a realistic margin of error of 3%. The gains with 3 or more RegionServers per Worker are identical to the previous case, so no benefit is generated.
Among the properties tested, only two of them resulted in the most efficient configuration to increase gains with 2 RegionServers per Worker. Adding 10GB of RAM to the RegionServers (hbase_regionserver_heapsize=30.720) and 4000 threads for DataNode data transfer (dfs.datanode.max.transfer.threads=20.480), we get 11% gain for workload A, and 21% for F, which are the two workloads including reads. Again, the gains with 3 RegionServers after optimizations involve no change. Although a 21% gain cannot be called significant, it is nonetheless interesting.
Finally, new properties have been tested but have not been able to bring any concrete benefit:
- io.file.buffer.size: size of the I/O buffer through the DataNode.
- dfs.datanode.handler.count: number of handlers available per DataNode to respond to requests.
- dfs.datanode.balance.bandwidthPerSec: maximum level of bandwidth that each DataNode can use.
- dfs.datanode.readahead.bytes: number of bytes to read in advance of the item being read.
- dfs.client.read.shortcircuit.streams.cache.size: size of the client’s cache during a shortcircuit read.
Metrics analysis
The analysis of various activity metrics allowed us to identify hypotheses explaining the gains obtained. The metrics in question, retrieved on each machine, are: the evolution of the CPU load (user, system), that of the RAM (used, free, swap), that of the I/O (number of transfers, read/write rate, request rate) and the distribution of the loads (run queue, load average, number of tasks waiting for the disk).
Hypotheses:
- Increasing the number of Datanode threads increases read/write requests to the disks, generating tasks waiting for available IOs. The default number of threads was therefore insufficient when adding a RegionServer to reach the performance threshold of the DataNodes.
- With the addition of RAM at the RegionServers, we can assume that reads are done at the BlockCache, thus reducing the number of read requests going to disk, which reduces tasks waiting for disk. This would explain the benefits of read workloads, negligible for write workloads, with or without optimization.
Therefore, we can say that the bottleneck is surely on the disks. Indeed, the insertion performance increases slightly thanks to the pressure that a second RegionServer places on the disks, but it does not go any further precisely because it depends only on the disks. Also, the read performance is better thanks to the pressure of the threads, but especially thanks to the enlargement of the various read caches. Moreover, it is interesting to note that the number of requests does not completely double when adding a second RegionServer. Without a bottleneck, the performance would not have doubled.
Adding disks
So far, the machines have been running with four 3 TB disks, but how would the performance change if they had more? 8 disks were therefore added to each machine. The test results are shown in the following table:
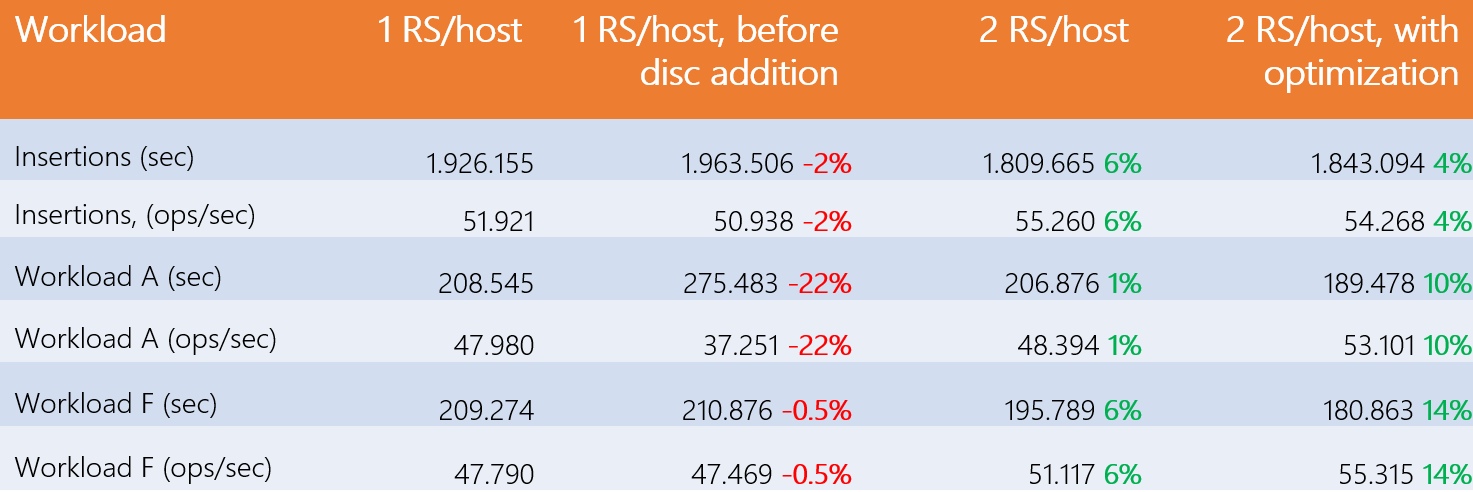
First of all, we notice a performance difference of 22% on workload A compared to the initial case, while they are more or less identical for the two other types of tests. On the other hand, on the same workload, the gains increase to 1% with 2 RegionServers per host, then 10% with optimization. The increase in the number of disks has therefore had a significant impact on the performance of our RegionServer, but the addition of an extra instance, even with optimization, is of little interest.
Conclusion
As we have seen, in our environment, write and read performance is far from being doubled by adding a second RegionServer on each Worker. The DataNode then acts as a software bottleneck and at best provides a 21% gain. RegionServers are optimized to drain maximum performance on their own, and work in a trio with Yarn Node Managers and HDFS DataNodes. This environment was designed to have only one RegionServer per Worker, as shown by the performance gain with a single RegionServer when adding disks.
On the other hand, this case can benefit a cluster with a surplus of regions. Indeed, the regions are equitably shared between each RegionServer, without causing any loss of performance. Also, for certain use cases such as workload F, the removal of a physical node can be considered in order to save the costs of licensing and operating it without incurring a significant drop in performance.
