


Deploy your containerized AI applications with nvidia-docker

Mar 24, 2022
- Categories
- Containers Orchestration
- Data Science
- Tags
- containerd
- DevOps
- Learning and tutorial
- NVIDIA
- Docker
- Keras
- TensorFlow [more][less]
Never miss our publications about Open Source, big data and distributed systems, low frequency of one email every two months.
More and more products and services are taking advantage of the modeling and prediction capabilities of AI. This article presents the nvidia-docker tool for integrating AI (Artificial Intelligence) software bricks into a microservice architecture. The main advantage explored here is the use of the host system’s GPU (Graphical Processing Unit) resources to accelerate multiple containerized AI applications.
To understand the usefulness of nvidia-docker, we will start by describing what kind of AI can benefit from GPU acceleration. Secondly we will present how to implement the nvidia-docker tool. Finally, we will describe what tools are available to use GPU acceleration in your applications and how to use them.
Why using GPUs in AI applications?
In the field of artificial intelligence, we have two main subfields that are used: machine learning and deep learning. The latter is part of a larger family of machine learning methods based on artificial neural networks.
In the context of deep learning, where operations are essentially matrix multiplications, GPUs are more efficient than CPUs (Central Processing Units). This is why the use of GPUs has grown in recent years. Indeed, GPUs are considered as the heart of deep learning because of their massively parallel architecture.
However, GPUs cannot execute just any program. Indeed, they use a specific language (CUDA for NVIDIA) to take advantage of their architecture. So, how to use and communicate with GPUs from your applications?
The NVIDIA CUDA technology
NVIDIA CUDA (Compute Unified Device Architecture) is a parallel computing architecture combined with an API for programming GPUs. CUDA translates application code into an instruction set that GPUs can execute.
A CUDA SDK and libraries such as cuBLAS (Basic Linear Algebra Subroutines) and cuDNN (Deep Neural Network) have been developed to communicate easily and efficiently with a GPU. CUDA is available in C, C++ and Fortran. There are wrappers for other languages including Java, Python and R. For example, deep learning libraries like TensorFlow and Keras are based on these technologies.
Why using nvidia-docker?
Nvidia-docker addresses the needs of developers who want to add AI functionality to their applications, containerize them and deploy them on servers powered by NVIDIA GPUs.
The objective is to set up an architecture that allows the development and deployment of deep learning models in services available via an API. Thus, the utilization rate of GPU resources is optimized by making them available to multiple application instances.
In addition, we benefit from the advantages of containerized environments:
- Isolation of instances of each AI model.
- Colocation of several models with their specific dependencies.
- Colocation of the same model under several versions.
- Consistent deployment of models.
- Model performance monitoring.
Natively, using a GPU in a container requires installing CUDA in the container and giving privileges to access the device. With this in mind, the nvidia-docker tool has been developed, allowing NVIDIA GPU devices to be exposed in containers in an isolated and secure manner.
At the time of writing this article, the latest version of nvidia-docker is v2. This version differs greatly from v1 in the following ways:
- Version 1: Nvidia-docker is implemented as an overlay to Docker. That is, to create the container you had to use nvidia-docker (Ex:
nvidia-docker run ...) which performs the actions (among others the creation of volumes) allowing to see the GPU devices in the container. - Version 2: The deployment is simplified with the replacement of Docker volumes by the use of Docker runtimes. Indeed, to launch a container, it is now necessary to use the NVIDIA runtime via Docker (Ex:
docker run --runtime nvidia ...)
Note that due to their different architecture, the two versions are not compatible. An application written in v1 must be rewritten for v2.
Setting up nvidia-docker
The required elements to use nvidia-docker are:
- A container runtime.
- An available GPU.
- The NVIDIA Container Toolkit (main part of nvidia-docker).
Prerequisites
Docker
A container runtime is required to run the NVIDIA Container Toolkit. Docker is the recommended runtime, but Podman and containerd are also supported.
The official documentation gives the installation procedure of Docker.
Driver NVIDIA
Drivers are required to use a GPU device. In the case of NVIDIA GPUs, the drivers corresponding to a given OS can be obtained from the NVIDIA driver download page, by filling in the information on the GPU model.
The installation of the drivers is done via the executable. For Linux, use the following commands by replacing the name of the downloaded file:
chmod +x NVIDIA-Linux-x86_64-470.94.run
./NVIDIA-Linux-x86_64-470.94.runReboot the host machine at the end of the installation to take into account the installed drivers.
Installing nvidia-docker
Nvidia-docker is available on the GitHub project page. To install it, follow the installation manual depending on your server and architecture specifics.
Nvidia-docker tools
We now have an infrastructure that allows us to have isolated environments giving access to GPU resources. To use GPU acceleration in applications, several tools have been developed by NVIDIA (non-exhaustive list):
- CUDA Toolkit: a set of tools for developing software/programs that can perform computations using both CPU, RAM, and GPU. It can be used on x86, Arm and POWER platforms.
- NVIDIA cuDNN: a library of primitives to accelerate deep learning networks and optimize GPU performance for major frameworks such as Tensorflow and Keras.
- NVIDIA cuBLAS: a library of GPU accelerated linear algebra subroutines.
By using these tools in application code, AI and linear algebra tasks are accelerated. With the GPUs now visible, the application is able to send the data and operations to be processed on the GPU.
The CUDA Toolkit is the lowest level option. It offers the most control (memory and instructions) to build custom applications. Libraries provide an abstraction of CUDA functionality. They allow you to focus on the application development rather than the CUDA implementation.
Once all these elements are implemented, the architecture using the nvidia-docker service is ready to use.
Here is a diagram to summarize everything we have seen:
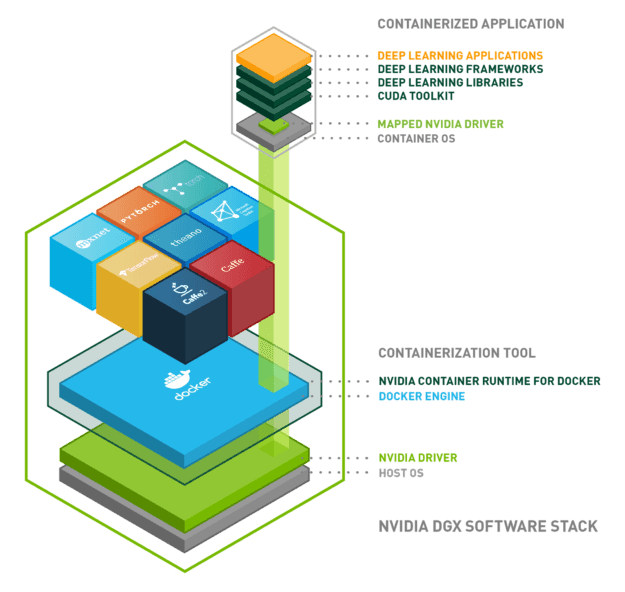
Conclusion
We have set up an architecture allowing the use of GPU resources from our applications in isolated environments. To summarize, the architecture is composed of the following bricks:
- Operating system: Linux, Windows …
- Docker: isolation of the environment using Linux containers
- NVIDIA driver: installation of the driver for the hardware in question
- NVIDIA container runtime: orchestration of the previous three
- Applications on Docker container:
- CUDA
- cuDNN
- cuBLAS
- Tensorflow/Keras
NVIDIA continues to develop tools and libraries around AI technologies, with the goal of establishing itself as a leader. Other technologies may complement nvidia-docker or may be more suitable than nvidia-docker depending on the use case.
