


Omid: Scalable and highly available transaction processing for Apache Phoenix

May 24, 2018
Never miss our publications about Open Source, big data and distributed systems, low frequency of one email every two months.
Apache Omid provides a transactional layer on top of key/value NoSQL databases. In practice, it is usually used on top of Apache HBase.
Credits to Ohad Shacham for his talk and his work for Apache Omid. This article is the result of my understanding of Apache Omid through online documentation and the conference given at the Dataworks Summit 2018 in Berlin.
Although you can work with Omid directly, it aims at being integrated as a transaction engine for Apache Phoenix. Currently, Phoenix transactions are still a beta feature with the Tephra engine. Thanks to a Transaction Abstraction Layer, you will soon be able to switch between Omid and Tephra transactional backend on Phoenix.
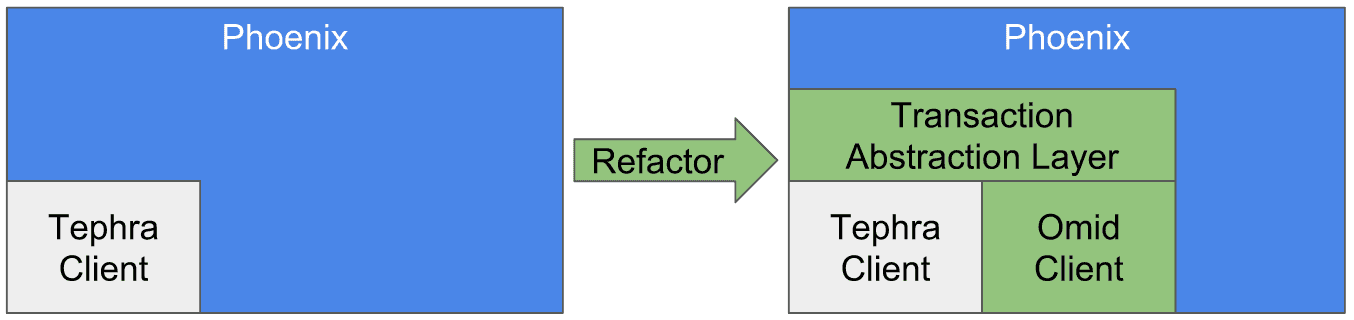
Why are both Tephra and Omid incubated by Apache?
From the Omid proposal:
Very recently, a new incubator proposal for a similar project called Tephra, has been submitted to the ASF. We think this is good for the Apache community, and we believe that there’s room for both proposals as the design of each of them is based on different principles (e.g. Omid does not require to maintain the state of ongoing transactions on the server-side component) and due to the fact that both - Tephra and Omid - have also gained certain traction in the open-source community.
These projects are still very close, but future improvements may justify the choice of one over the other for specific use cases.
Omid objectives
Omid ensures transactions follow the ACID properties:
- Atomic: “all-or-nothing” - no partial effect observable;
- Consistent: the DB transition from one valid state to another;
- Isolated: appear to execute in isolation;
- Durable: committed data cannot disappear.
With its integration in Phoenix, this can be achieved with SQL transactions.
Omid internals
Omid has to ensure that transactions do not have conflicting operations. The main component (TSO: The Server Oracle) role is to detect these conflicts.
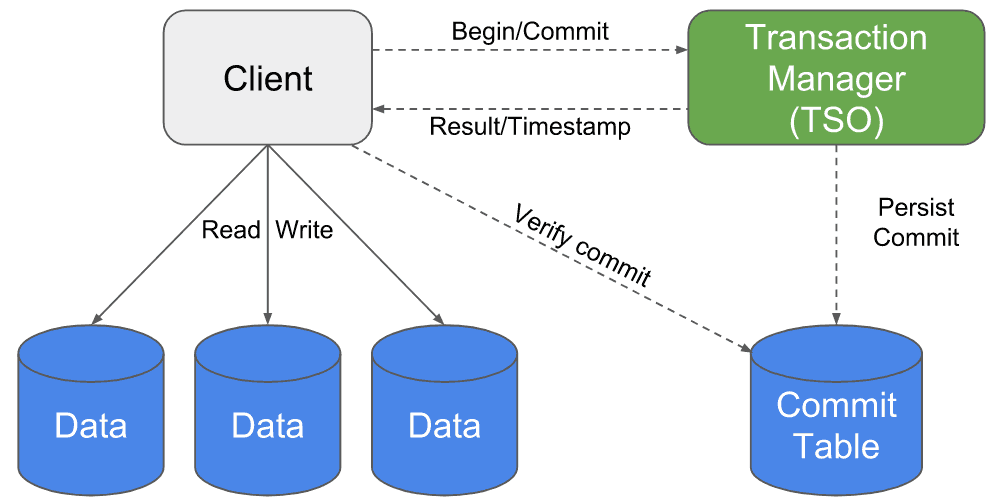
Here is a simplified step-by-step explanation:
- First, the client begins a transaction. The TSO returns a read timestamp so that the transaction never reads data that exceeds this timestamp. It writes data using a temporary timestamp (null) indicating that the operation has not been validated yet (it is called a tentative update);
- It then commits the operation to the TSO. If no conflict is found, the TSO persists the commit in the commit table (CT) with a given commit timestamp;
- The client checks if the commit has been persisted in the commit table. In that case, it updates the data to give it the correct timestamp (commit timestamp). It then removes the commit from the commit table.
When a transaction is reading data, it has to check whether this data commit timestamp is less than the transaction read timestamp. If not, it checks the previous version of the data and does the same process.
However, we said that a transaction first writes data with a null timestamp (tentatively) before it has been commited. In case a transaction reads data with a null timestamp, it has to check directly in the commit table if its commit timestamp is less than the transaction read timestamp. If it is found in the CT, the transactional client updates the data with the correct commit timestamp (this is called the healing process, which optimizes access to the CT for other clients). If not, it goes to the previous version of the data.
Omid recent and future features
Extended snapshot isolation
When a transaction begins, the snapshot isolation ensures that other transactions that occur at the same time on the same rows will not affect the current transaction. In case a write-write conflict occurs, it will just be detected by the TSO, and one of the transaction will be aborted.
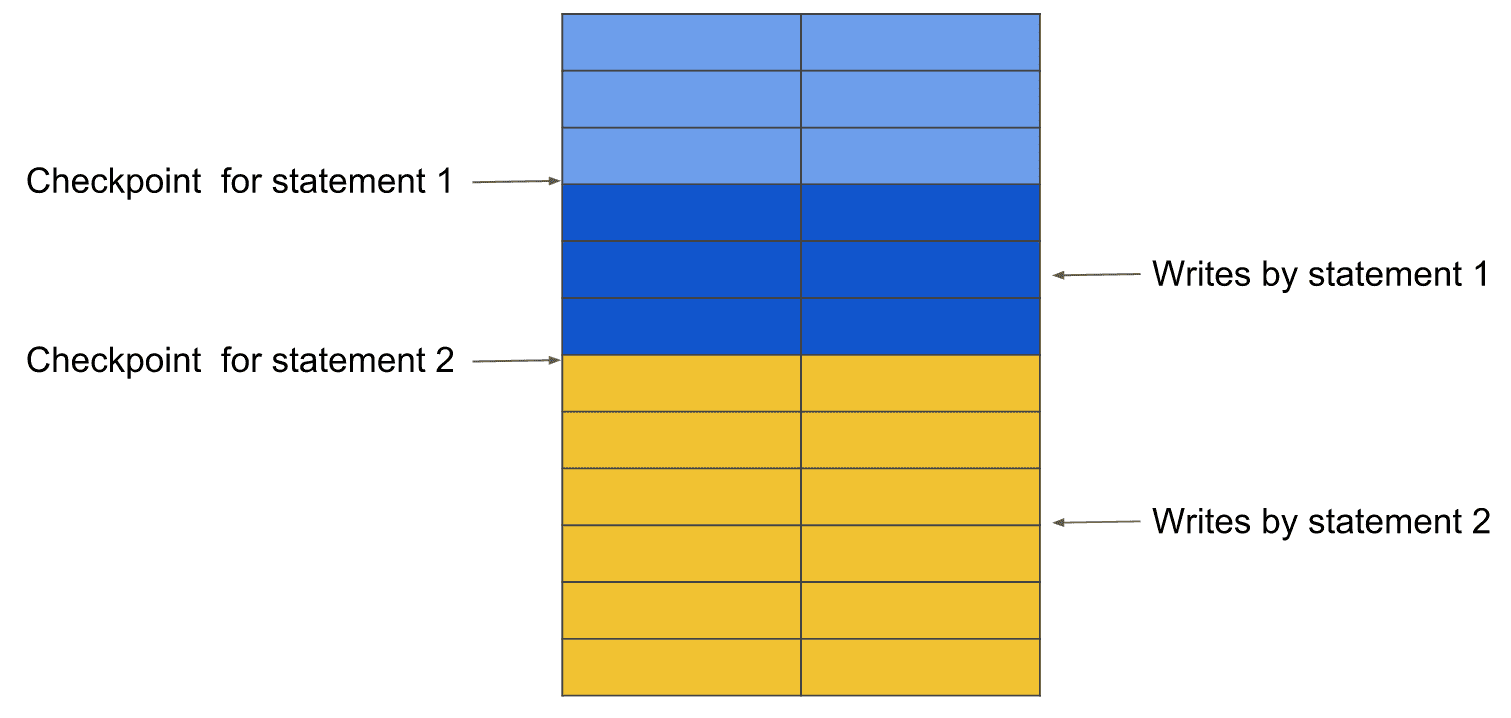
The extended snapshot isolation ensures that you can write and read concurrently in the same transaction. What you write in the current snapshot will be taken into account for the next query.
Consider the following transaction:
CREATE TABLE T (ID INT);
...
BEGIN;
INSERT INTO T
SELECT ID+10 FROM T;
INSERT INTO T
SELECT ID+100 FROM T;
COMMIT;The first transaction only sees the snapshot until the first checkpoint. The checkpoint is then pushed to the last row written by the first statement. The same thing goes for the second statement.
High availability
In the current architecture, the TSO is a single point of failure. To enable high availabity, we add a secondary TSO so that we can have a primary/backup system. To avoid a split brain scenario (in case the primary TSO is not actually down), the primary TSO regularly checks if it has been replaced by a secondary TSO, and if so, kills himself. We do not want to use synchronization mechanisms (for example a lock), as it would imply a check for each commit, therefore affecting the system performance.
Because there is no synchronization mechanism, there is a delay before the primary TSO actually kills himself. During that time, we can have conflictual transactions that need to be handled. To prevent that, two conditions need to be satisfied:
- All the timestamps assigned by the new TSO must be greater than the timestamps assigned by the old TSO;
- The TSO cannot persists commits that does updates with a commit timestamp lesser than the read timestamp of other transactions.
Low latency
A low latency alternative to the current design has been mentioned during this talk. Instead of having the TSO persisting commits in the commit table, the Writes operation to the CT will be handled directly by the client.
To conclude, one key takeaway is to keep in mind that Apache Phoenix can now handle transactions (beta), and it will propose a new backend for its transactions: Omid. While most of what we have discussed here is not available yet, it will come in the near future.
References
- https://omid.incubator.apache.org/
- https://fr.slideshare.net/Hadoop_Summit/omid-scalable-and-highly-available-transaction-processing-for-apache-phoenix
- https://wiki.apache.org/incubator/OmidProposal
- http://yahoohadoop.tumblr.com/post/132695603476/omid-architecture-and-protocol
- http://yahoohadoop.tumblr.com/post/138682361161/high-availability-in-omid
- https://issues.apache.org/jira/browse/PHOENIX-3623
- https://issues.apache.org/jira/browse/OMID-82
