


Développement accéléré de modèles avec H2O AutoML et Flow

10 déc. 2020
- Catégories
- Data Science
- Formation
- Tags
- Automation
- Cloud
- H2O
- Machine Learning
- MLOps
- On-premises
- Open source
- Python [plus][moins]
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
La construction de modèles de Machine Learning (ML) est un processus très consommateur de temps. De plus, il requière de bonne connaissance en statistique, en algorithme de ML ainsi qu’en programmation. Pour finir, il faut également réussir à identifier et traduire un besoin métier en une formule mathématique. L’ensemble du processus se décompose en plusieurs étapes. Par exemple, quand nous recevons un nouveau jeu de données, nous devrons l’explorer dans un 1er temps : décider quelles colonnes peuvent être utiles par apport à notre besoin métier, remplacer les valeurs manquantes, vérifier la corrélation, la distribution ou le nombre de classes de nos variables. Ce n’est qu’ensuite que nous pouvons décider quel modèle est le plus approprié et tester ses performances. Puis afin d’optimiser ses performances et avoir le modèle le plus performant, nous devrons régler les hyper paramètres et sélectionner les métriques les plus appropriées. Coder et lancer chacune de ses étapes séquentiellement demande un grand investissement en temps. Nous aurions pu consacrer ce temps autrement comme pour acquérir une meilleure connaissance des parcours clients.
Un grand nombre de frameworks ont été créés afin d’automatiser au moins une des parties. Cela permet de réduire les actions humaines nécessaires et d’augmenter le nombre de modèles testés automatiquement ou de fonctionnalités générées. Nous alons découvrir l’un d’entre eux, la plateforme open source H2O, via l’API Python et H2O Flow, l’interface Web.
Introduction à AutoML et H2O
Automatic Machine Learning (AutoML) est une approche du ML, où chaque tâche peut être individuellement automatisées. Ces tâches peuvent être :
- pré-traitement des données
- fonctionnalités d’ingénierie, d’extraction et de sélection
- tester de nombreux modèles de différentes familles
- optimisation des hyper-paramètres.
L’objectif d’AutoML est différent selon qu’il s’applique au Deep Learning ou au Machine Learning :
- Deep Learning : images/vidéos/textes, Essayer de définir un réseau de neurones
- Machine Learning : données tabulaires, trouver le meilleur modèle avec le moins d’effort
Dans cet article, nous développerons un exemple dans un contexte de ML. La solution open source H2O nous aide grandement dans la modélisation et le réglage des hyper paramètres et dans une certaine mesure avec le pré-traitement des données (e.g. remplacement des valeurs manquantes). Pour automatiser le travail de fonctionnalités d’ingénierie, l’entreprise H2O.ai a développé DriverlessAI, qui est un produit propriétaire avec un essai gratuit de 21 jours disponible.
H2O est une solution open source de prédiction “in-memory” qui supporte les calculs distribués. Le logiciel peut être lancé localement sur son PC ou dans un cluster multi-noeud, sur votre plateforme Hadoop on-premises ou alors sur des fournisseurs de Cloud. Il n’est pas limité par la taille du cluster. Ainsi, vous pouvez gérer de grands ensembles de données et calculer des modèles en parallèle. Lorsque vous travaillez sur un cluster H2O, les données sont réparties sur plusieurs nœuds. Les algorithmes de base sont écrits en Java et des API sont disponibles pour Python, R, Scala et H2O Flow, leur interface web. Il existe également une version qui peut être utilisée avec Spark, appelée Sparkling Water. Les connecteurs natifs à différents types de stockages de données facilitent l’importation des données (système de fichiers local, fichiers distants via URL, S3, HDFS, JDBC et Hive) et plusieurs formats de fichiers différents sont pris en charge (Parquet, Avro, ORC, CSV, XLS/XLSX, ARFF et SVMLight).
Nous pouvons choisir parmi de nombreux algorithmes supervisés et non supervisés :
- non supervisés : Aggregator, Generalized Low Rank Models, Isolation Forest, K-Means Clustering et Principal Component Analysis
- supervisés : Cox Proportional Hazards, Deep Learning, Distributed Random Forest, Generalized Linear Model, Generalized additive models, Gradient Boosting Machine, Naive Bayes Classifier, RuleFit et Support Vector Machine. Nous pouvons les optimiser de manière ‘classique’ un par un, ou nous pouvons utiliser la fonction AutoML, qui construira de nombreux modèles au cours de chaque expérience. Nous pouvons également créer des ensembles empilés ou combiner plusieurs modèles en un “metalearner” plus performant.
Une fois qu’un modèle est construit et vérifié, nous pouvons le télécharger en tant qu’objet Java déployable sur n’importe quel environnement Java.
H2O Flow est un notebook basé sur une interface Web qui permet de gérer l’intégralité des workflows ML. Chaque clic génère automatiquement du code CoffeeScript. Ces clics matérialisés nous permettent de sauvegarder les étapes exactes du processus (appelé flux) et facilitent le partage et la reproductibilité. Flow a des fonctionnalités très limitées pour la préparation des données et l’ingénierie des fonctionnalités. Sa puissance devient évidente dans la phase de modélisation. Lorsque nous cliquons sur le workflow, il expose tous les paramètres des méthodes et des algorithmes avec une brève description. Étant donné que les paramètres sont nombreux, c’est beaucoup plus rapide que de lire de la documentation, en particulier pour les Data Scientists et les Data Analysts moins expérimentés. Il crée automatiquement une grande quantité de tracés, des tracés de corrélation partielle, des AUC, des graphiques de gains/élévation à l’importance variable et nous pouvons les parcourir sans effort. Tout cela diminue considérablement le temps et les efforts consacrés à la visualisation et augmente également la compréhension du modèle étudié.
De plus, nous n’avons pas besoin de choisir entre la polyvalence d’une API et la convivialité de Flow. Ils peuvent être utilisés conjointement, afin de bénéficier du meilleur des deux mondes. Nous allons étudier un exemple dans lequel les données sont préparées dans Jupyter Notebook avant d’être enregistrées. Ensuite, nous allons l’importer dans Flow et passer par les étapes suivantes : analyse, modélisation avec AutoML, prédiction et pour la fin, nous examinerons les graphiques de performance. C’est représentatif d’une utilisation classique, dans laquelle nous minimiserons le codage et maximiserons l’utilisation de l’interface graphique. Les Data Scientists plus expérimentés préféreront définir et démarrer la phase de modélisation en programmant et utiliser Flow pour visualiser la progression et les résultats.
Configuration de l’environnement
Les pré-requis sont Java et un navigateur Web. J’ai utilisé Arch Linux avec Java 13 OpenJDK et Firefox 78.0.2. La version de H2O est 3.30.0.7 et la version de Python est 3.7.7.
Installation de Flow
Pour lancer Flow sur notre ordinateur, nous installons la dernière version de H2O téléchargeable en ligne. Décompressé le fichier “.zip”, puis allez dans le dossier et lancer h2o.jar :
cd h2o-3.30.0.7
java -jar h2o.jarH2O utilise par défaut le port 54321. Une fois H2O lancé, allez sur votre navigateur web à l’adresse suivante http://localhost:54321. Flow utilise sa propre terminologie et son mode de fonctionnement. Vous pouvez vous familiariser avec cette solution grâce à la documentation du projet.
Installation de H2O pour python
Nous avons utilisé Miniconda, version 4.8.3.
Création de l’environnement virtuel :
$ conda create --name env_h2o python=3.7
$ conda activate env_h2oInstallation des dépendences :
pip install requests
pip install tabulate
pip install "colorama>=0.3.8"
pip install futureInstallation de la dernière version stable de H20 :
pip install http://h2o-release.s3.amazonaws.com/h2o/rel-zahradnik/7/Python/h2o-3.30.0.7-py2.py3-none-any.whlDataset
Les datasets utilisés pour cette démo sont client_train.csv et invoice_train.csv sur la détection des fraudes dans la consommation d’électricité et de gaz.
Pre-processing des données avec l’API python
La partie pré-processing de notre dataset a été réalisée dans un notebook jupyter.
Initialisation du cluster H2O
# start the H2O cluster
import h2o
h2o.init()Ces commandes permetent de démarrer le cluster H2O et donnent une multitude d’informations telles que : mémoire disponible, nombre de cœurs autorisés et address HTTP pour accéder à Flow. Ici, nous initialisons le cluster avec des paramètres par défaut. Ils sont nombreux et peuvent être modifiés.
Chargement des datasets
Notez que H2O sépare le téléchargement de fichiers (les données sont poussées du client vers le serveur) et l’importation (extrait les données déjà présentes sur le serveur). Puisque nous exécutons un serveur H2O sur un ordinateur local, les deux méthodes se comportent de la même manière. Nous importerons des fichiers avec des types de colonnes définies pour effectuer moins de conversions plus tard.
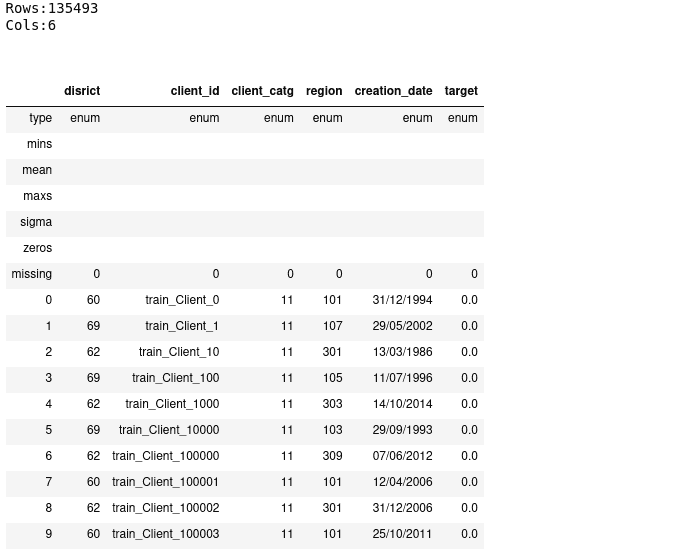
client_types = ['enum', 'enum', 'enum', 'enum', 'enum', 'enum']
client = h2o.import_file("../h2o/data/client_train.csv", col_types=client_types)
client.describe()
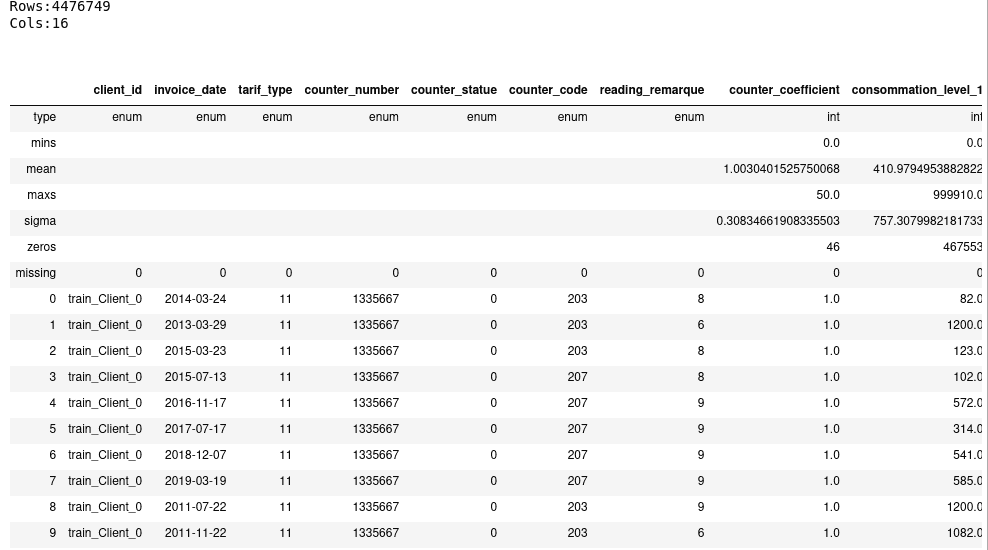
invoice_types = ['enum', 'enum', 'enum', 'enum', 'enum', 'enum', 'enum', 'int', 'int', 'int', 'int', 'int', 'enum', 'enum', 'enum', 'enum']
invoice = h2o.import_file("../h2o/data/invoice_train.csv", col_types=invoice_types)
invoice.describe()
Pre-preprocessing de données
- Fusion des tables
clientetinvoice: H2O implémente deux méthodes afin de fusionner (radix et hash method), qui permettent une fusion rapide même lorsque nous avons des gros volumes de données. Cependant, les colonnes utilisées pour les fusionner ne peuvent pas être du typestring.
client_invoice = invoice.merge(client)- Changement d’une colonne de type date en type time : H2O reconnait de manière automatique deux types de format de date lorsqu’il parse le fichier (yyyy-MM-dd et dd-MMM-yy). Vous aurez besoin de convertir les autres de vous-mêmes.
client_invoice['creation_time'] = client_invoice['creation_date'].as_date('%d/%m/%Y')
client_invoice['invoice_time'] = client_invoice['invoice_date'].as_date('%Y-%m-%d')- Renommage des colonnes
districtetcounter_statue:
client_invoice.rename(columns={'disrict':'district', 'counter_statue':'counter_status'})- Remplacement des valeurs manquantes avec mode :
client_invoice.impute("counter_status", method="mode")- Feature engineering : créer une nouvelle colonne indiquant depuis combien de temps une personne est client lors de la réception de la facture. Nous supprimerons tous les clients dont la date de facturation était antérieure à la date de création.
client_invoice['fidelity_period'] = client_invoice['invoice_time'] - client_invoice['creation_time']
client_invoice['total_consommation'] = sum(client_invoice[8:11])
client_invoice = client_invoice[client_invoice["fidelity_period"] > 0, :]- Sauvegarde des données : Nous avons terminé le pré-traitement des données. Si nous voulons l’utiliser avec Flow, nous devons le conserver et l’importer dans Flow.
h2o.export_file(client_invoice,"../h2o/data/client_invoice_1.csv")Dans ce court exercice, nous avons vu plusieurs méthodes de préparation de données, natives de H2O, et travaillant sur des trames H2O distribuées. H2O propose une large gamme de fonctionnalité mais il y en a beaucoup d’autres qui ne sont pas (encore) implémentées. Dans ces cas, nous pouvons utiliser d’autres bibliothèques comme Pandas et scikit-learn. Nous pouvons facilement transformer une trame H2O en Pandas, mais nous devons garder à l’esprit que ce dernier n’est pas distribué.
Modeliser avec Flow
Ouvrer l’interface Flow http://localhost:54321.
Importer les données
Si vous tapez le chemin du dossier avec vos données et appuyez sur “Enter”, vous obtiendrez une liste de tous les fichiers du dossier. Vous pouvez en sélectionner un ou plusieurs si vos données sont stockées dans un format distribué.
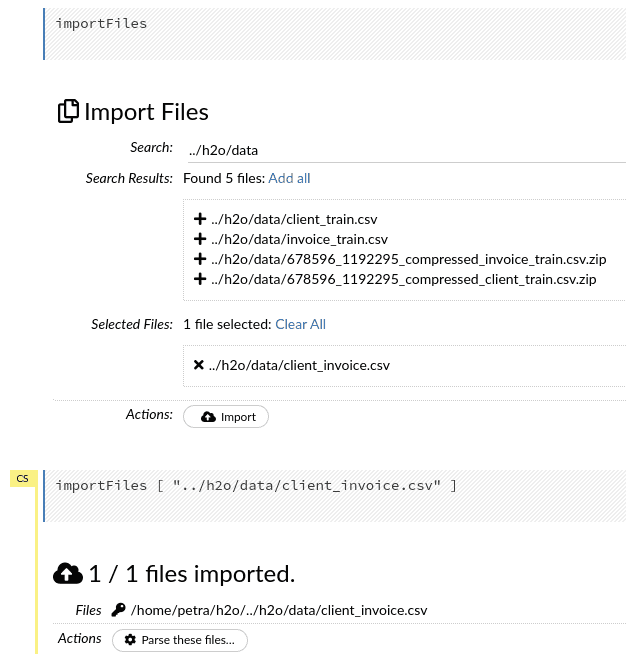
Parse
Lors de l’importation, le schéma est automatiquement déduit. Si nous ne sommes pas satisfaits des types de données reconnues dans les colonnes, ou du séparateur et de l’en-tête choisies par l’analyseur, nous pouvons facilement les modifier à l’aide de menus déroulants et de boutons radio.
Vous trouverez ci-dessous, le schéma du bloc de données client_invoice que nous allons utiliser, modifions donc ce qui est nécessaire. Ici, vous pouvez voir qu’avec des ensembles de données avec de nombreuses colonnes, cela devient une tâche très fastidieuse.
{'client_id': 'Enum',
'invoice_date': 'Enum',
'tarif_type': 'Enum',
'counter_number': 'Enum',
'counter_status': 'Enum',
'counter_code': 'Enum',
'reading_remarque': 'Enum',
'counter_coefficient': 'Numeric',
'consommation_level_1': 'Numeric',
'consommation_level_2': 'Numeric',
'consommation_level_3': 'Numeric',
'consommation_level_4': 'Numeric',
'old_index': 'Enum',
'new_index': 'Enum',
'months_number': 'Enum',
'counter_type': 'Enum',
'district': 'Enum',
'client_catg': 'Enum',
'region': 'Enum',
'creation_date': 'Enum',
'target': 'Enum',
'creation_time': 'Numeric',
'invoice_time': 'Numeric',
'fidelity_period': 'Numeric',
'total_consommation': 'Numeric'}
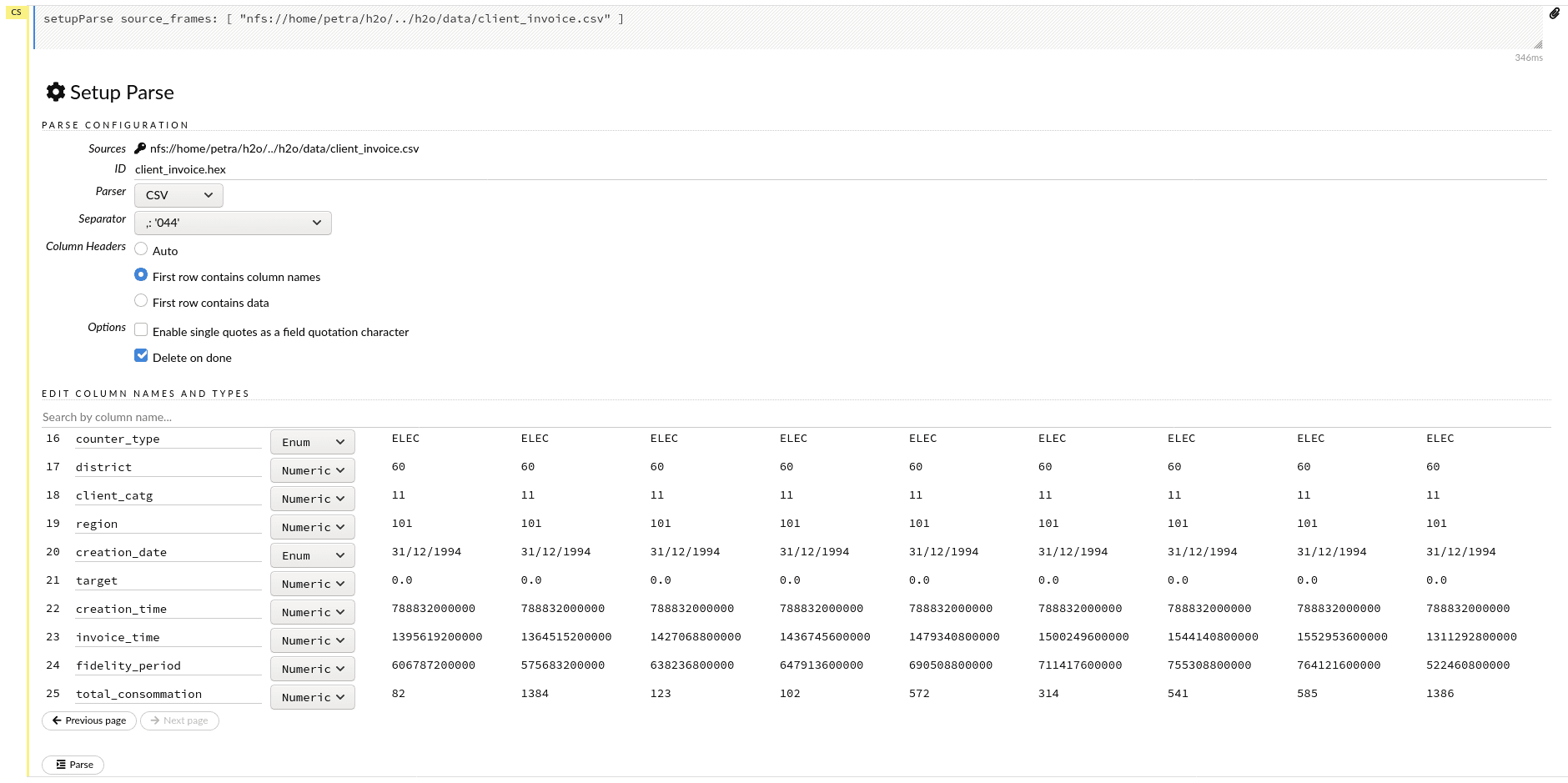
Cliquer sur Parse afin de démarrer le parsing.

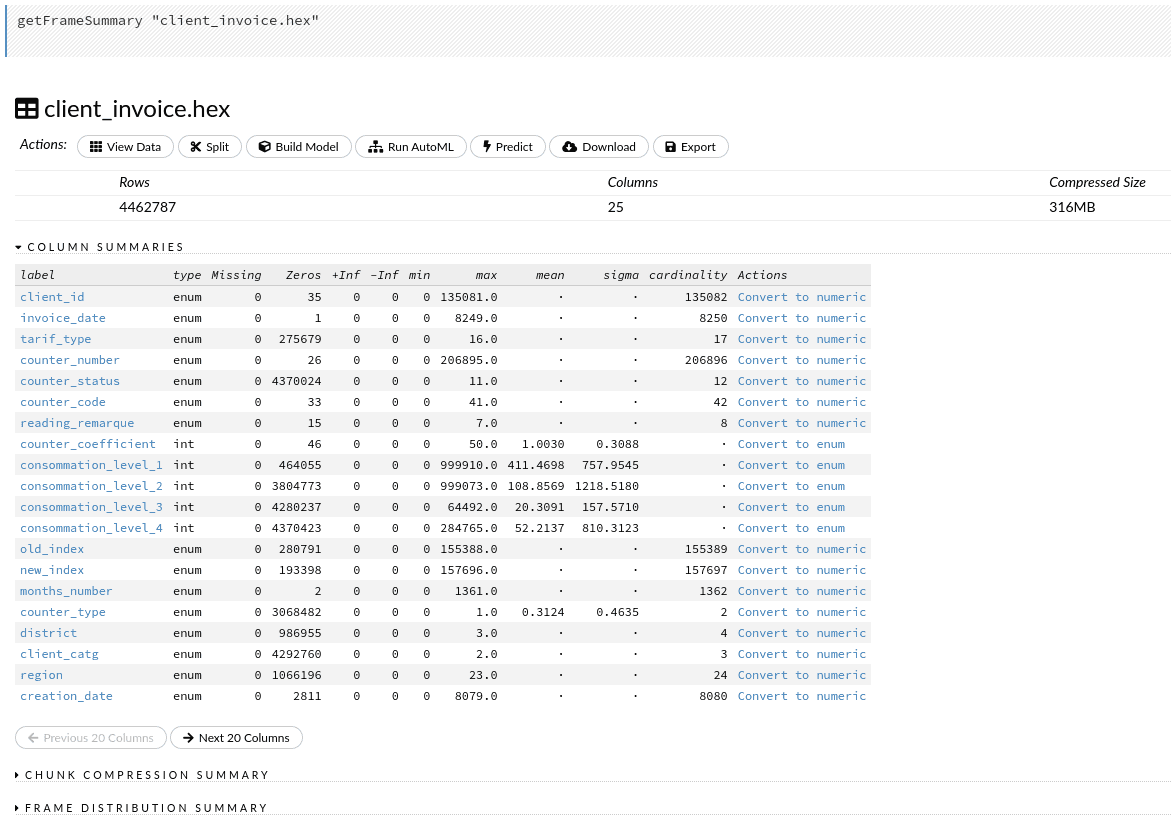
La prochaine action que nous pouvons faire est View. Nous pouvons à nouveau inspecter le tableau, cette fois avec des statistiques récapitulatives de toutes les colonnes. Si nous le comparons avec la sortie .describe() du notebook, nous pouvons apprécier les informations supplémentaires sur la cardinalité des variables catégorielles.
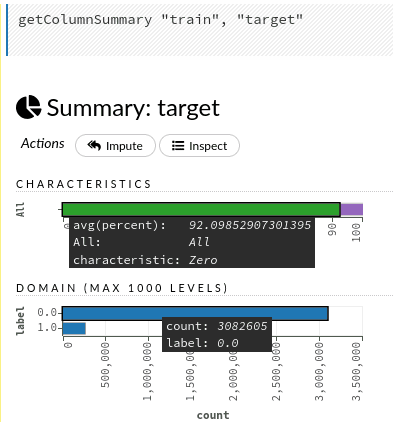
Si nous cliquons sur le nom d’une colonne, nous découvrirons encore plus de détails sur chaque colonne. Essayons avec la variable de réponse target. Cliquer sur le nom ouvre les graphiques avec le rapport des zéros par rapport aux autres valeurs et la distribution des étiquettes. «Inspect» au-dessus des graphiques nous conduit aux données brutes utilisées pour créer les deux graphiques. De plus, si nous n’avons pas remplacé les données manquante auparavant, nous pourrions le faire à cette étape.
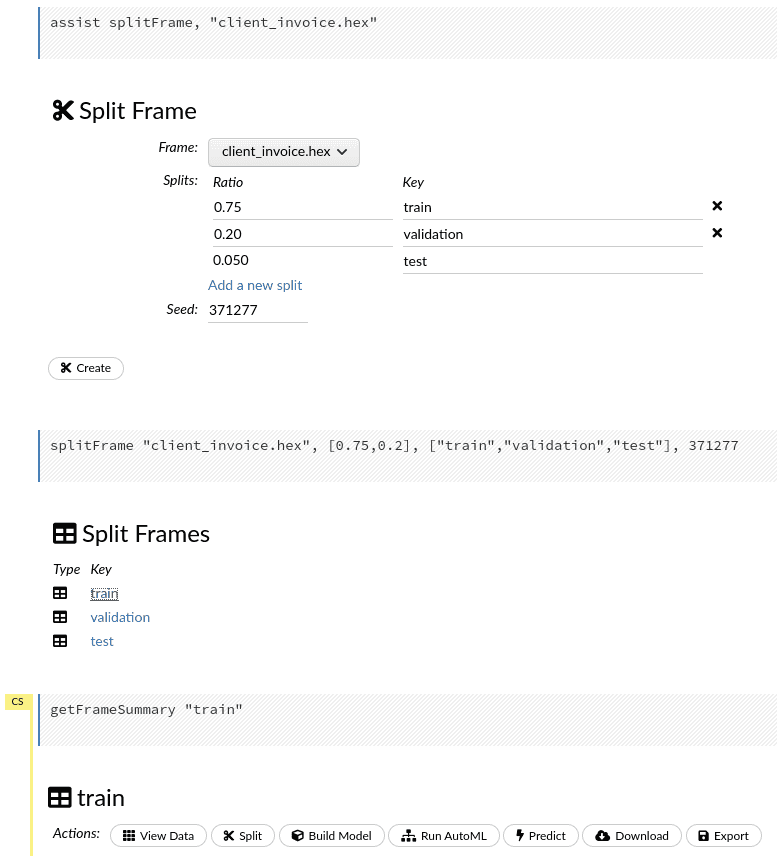
Split
Maintenant nous allons séparer les données dans train, validation, et test (75%, 20%, 5% respectivement). Créer les frames en appuyant sur create et cliquer sur train afin d’accéder à la liste d’action.
Run AutoML
Nous avons atteint le stade où nous pouvons lancer l’exécution avec run AutoML. Tout d’abord, nous devons sélectionner l’entrainement et la base de données de validation puis spécifier la variable de réponse.

Ensuite, nous devons cocher les colonnes que nous voulons exclure de la modélisation. Nous souhaitons conserver les suivants :
['tarif_type', 'counter_status', 'counter_code', 'reading_remarque', 'counter_coefficient', 'consommation_level_1', 'consommation_level_2', 'consommation_level_3', 'consommation_level_4', 'counter_type', 'district', 'client_catg', 'fidelity_period', 'total_consommation']Étant donné que les fraudes sont des événements rares, les ensembles de données pour la prévision de la fraude ont tendance à être fortement déséquilibrés. Dans notre cas, 7,9% des instances représentent des fraudes. Nous utiliserons l’option balance_classes, qui nous aidera à gérer ce problème.

On peut exclure les algorithmes qui ne nous intéressent pas. Pour illustrer, excluons le Deep Learning. Nous spécifierons également l’heure à laquelle AutoML doit s’exécuter avant de commencer à créer des modèles empilés. Je l’ai réglé à 600 secondes et le temps d’exécution totale était de 14,5 minutes, y compris la construction de deux modèles empilés à la fin.

Une fois l’intégralité des paramètres définie, cliquons sur Build models.
Prediction
Maintenant que les modèles sont formés et validés, nous pouvons les tester sur notre ensemble de données test. Nous devons revenir à nos Split Frames et sélectionner la trame test. Dans la liste d’actions, nous sélectionnons Predict et dans le menu déroulant Model qui est le modèle que nous aimerions utiliser.
Metrics et Plots
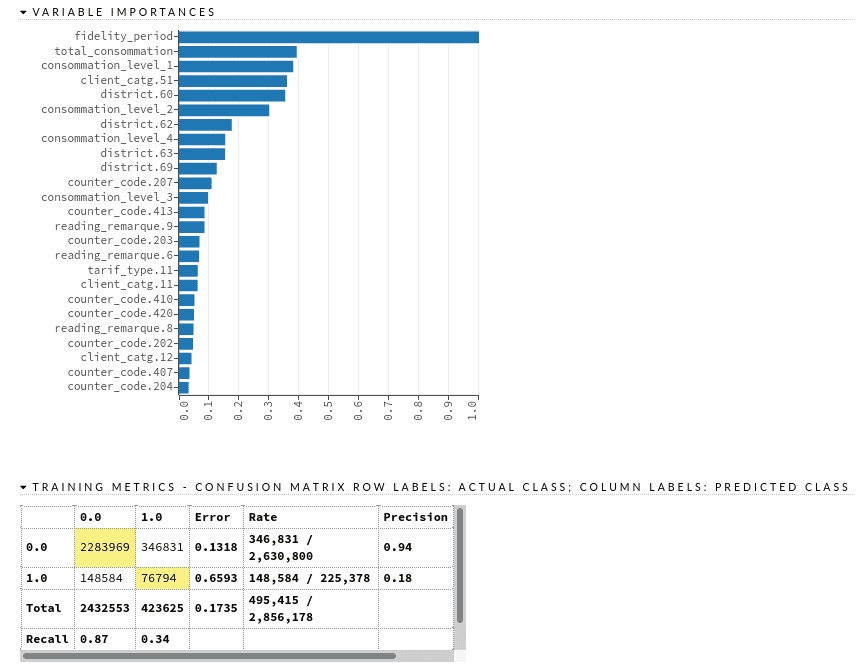
Pour explorer en détail les performances d’un modèle, nous cliquons sur son nom dans le classement après une exécution d’AutoML, où nous pouvons obtenir la liste de tous les modèles de notre environnement avec la fonction getModels. Ici, nous pouvons trouver des visualisations de différentes métriques (logloss, auc), un graphique d’importance variable, des matrices de confusion, des tables de gain/élévation, une liste de paramètres de modèle, des rapports de validation croisées, etc.
Export des Modèles
Vous pouvez exporter votre modèle préféré sous forme de code Java et l’exécuter sur n’importe quel environnement Java. Cela réduit la nécessité de traduire le modèle à partir du code Python ou R dans un langage utilisé en production et réduit les risques d’erreurs d’implémentation potentielle. De plus, en tant qu’objet Java, le modèle est découplé de l’environnement H2O.
Conclusion
Dans ce didacticiel, nous avons vu un moyen rapide et sans effort de créer des modèles avec H2O. En outre, le cadre nous donne des informations sur les performances du modèle et l’importance des fonctionnalités, ce qui nous aide à comprendre et à interpréter les modèles. Il entraîne plusieurs dizaines de modèles en utilisant une validation croisée multipliée par n en quelques heures ou quelques jours, selon la taille du jeu de données et la qualité de la formation que vous souhaitez. Il peut répondre à plusieurs questions importantes telles que “Quelle famille modèle fonctionne le mieux ?” et “Quelles sont les variables les plus importantes ?“. Il fournit de bonnes valeurs de départ pour les paramètres du modèle, que nous pouvons encore optimiser. Mais pour obtenir les meilleures performances possibles, la déclinaison open source d’H2O ne suffit pas et nous vous invitons a regarder l’offre proposée par H2O.ai, la société à l’initiative du projet open source. Par exemple, le réglage automatisé des hyper-paramètres est assez basique et il manque la recherche de grille optimisée. De plus, les données doivent être préparées ailleurs. Néanmoins, cela accélère considérablement les étapes initiales de la modélisation et réduit la quantité de code à écrire, afin que d’investir plus de temps dans la compréhension des cas d’usage sous-jacents.
