


H2O in practice: a Data Scientist feedback

Sep 29, 2021
- Categories
- Data Science
- Learning
- Tags
- Automation
- Cloud
- H2O
- Machine Learning
- MLOps
- On-premises
- Open source
- Python [more][less]
Never miss our publications about Open Source, big data and distributed systems, low frequency of one email every two months.
Automated machine learning (AutoML) platforms are gaining popularity and becoming a new important tool in the data scientists’ toolbox. A few months ago, I introduced H2O, an open-source platform for AutoML, with tutorial. Recently, I had a great opportunity to test it in practice. I had been working with our client, EDF Lab, together with ENEDIS. Both companies are major players in the French electricity market, ENEDIS being the network maintainer and EDF the major electricity supplier. The use-case covered the preventive maintenance of an underground low-tension electrical network. More specifically, the question was how to detect the segments of cables (feeders) that need to be replaced to prevent power cuts. The use-case was extensively studied and published previously.
Several models were developed beforehand. Therefore, the purpose of the mission was not the modeling itself but rather to estimate the added value of AutoML. Will it shorten the time of modeling and/or produce better models? We started with the comparison of existing frameworks. A great benchmark can be found here. Probably the most restrictive criterion for the selection is the open source nature of the framework. Namely, many AutoML frameworks are proprietary. H2O was estimated to be the most suitable for the task. Our task was to understand its functioning, its entry barrier, its performance on real-world data and to compare the model quality built with AutoML with the in-house reference models.
We would like to share our experience, pointing out which features we liked and which ones we were missing with H2O. Keep in mind that we are talking about the open-source version. Driverless AI, the commercial solution from H20.ai, might behave differently and it includes many additional features.
Since we covered the basics of H20 before, we will dive directly into specific topics this time:
- How does the H2O AutoML function work:
- How does it choose the algorithms to be tested?
- What difference does it make if we define
max_modelsormax_runtime_secs? - Does it traverse the pre-defined list of algorithms always in the same order?
- Difference between H2O AutoML grid search and classical grid search.
- Optimization (stopping) metrics.
- The benefit of stacked ensembles.
- Data import and conversion to H2OFrame.
- Multiple connections to the same session.
Dataset and environment
Open-source H2O supports only basic functionalities for data preparation and it doesn’t support automatic feature engineering. Thus, we were using an already prepared dataset, composed of the data from 2018 and 2019. It contained the descriptors of the network properties and the information about the incidents for each feeder. The train and test set had just over 1 million rows with 434 columns each. The data was imported from a Parquet file format. They were clean and ready to use. The task was the classification of a heavily unbalanced dataset (< 0.5% of class 1). AUCPR was used as an optimization metric during training. For the final model evaluation, two business metrics were calculated, both representing the number of failures on two different cumulative lengths of feeders to be replaced. 5-fold cross-validation was used to validate the models.
- H2O_cluster_version: 3.30.0.3\
- H2O_cluster_total_nodes: 10\
- H2O_cluster_free_memory: 88.9 Gb\
- H2O_cluster_allowed_cores: 50\
- H2O_API_Extensions: XGBoost, Algos, Amazon S3, Sparkling Water REST API Extensions, AutoML, Core V3, TargetEncoder, Core V4\
- Python_version: 3.6.10 final
Results
Which models will the H2O AutoML function test?
H2O AutoML has a pre-defined list and number of models, which will be automatically built during the training. Hyperparameter grids for grid search are also pre-defined. The documentation states:
The current version of AutoML trains and cross-validates the following algorithms (in the following order):
- three pre-specified XGBoost GBM (Gradient Boosting Machine) models
- a fixed grid of GLMs
- a default Random Forest (DRF)
- five pre-specified H2O GBMs
- a near-default Deep Neural Net
- an Extremely Randomized Forest (XRT)
- a random grid of XGBoost GBMs
- a random grid of H2O GBMs
- a random grid of Deep Neural Nets.
In some cases, there will not be enough time to complete all the algorithms, so some may be missing from the leaderboard. AutoML then trains two Stacked Ensemble models.
List of the parameters for tuning
Random Forest and Extremely Randomized Trees are not grid searched (in the current version of AutoML), so they are not included in the list below.”
This setup is very helpful in the initial phases of modeling. We can test many different models with one function call. We don’t need to spend time deciding what model will be the most suitable for the problem and what to include in the grid search. Instead, we can run the default set of models and dive deeper based on the results.
If we are not interested in all of the algorithms or if we would like to shorten compute time (since the full run can be long), we can specify the ones we want to include/exclude with include_algos and exclude_algos parameters. For example, after the first run, we saw that Deep Neural Nets were performing the worst.
Besides, the explainability of the model could be important for the project, so we excluded Deep Neural Nets from all the following trainings. On the other hand, while testing H2O AutoML parameters (like balance_classes, nfolds, etc.), we noticed that XGBoost (XGB) always performed much better than the other algorithms. Eventually, we included only XGB, to be able to exploit grid search as much as possible in a given time.
Does H2O AutoML traverse the list of algorithms always in the same order?
Yes. If you look at the list, you will notice that at the beginning, multiple models with fixed parameters are trained. AutoML grid search is placed in the second half of the list. Since grid search could find better parameters than the default ones, we need to make sure to give enough time or sufficient number of models to AutoML. Like that, it will finish the default models and continue with the grid search. Here are several ways to achieve it:
- sufficiently long run time
- constructing a sufficient number of models
- selecting a small number of algorithms to be tested
- defining modeling plan, where we can specify which models from the list should be built. However, we still need to give enough time and/or a sufficient number of models for AutoML to go through the entire plan. Otherwise, it will not complete everything.
What difference does it make if I define max_models or max_runtime_secs?
To specify when the training will end, we define either the maximal number of models to be built (max_models) or the maximal duration of the training (max_runtime_secs). If both are specified, the training stops after the first condition is satisfied.
When defining max_models, the models are trained until some pre-defined stopping point is reached. When defining max_runtime_secs, AutoML will allocate the time slots relative to the listed models. When the max_runtime_secs is up, the training stop. We didn’t find any documentation on the allocation of the time slots. Consequently, training under the max_runtime_sec condition might not reach the same level of convergence as under the max_models. A demonstration is in the image below.
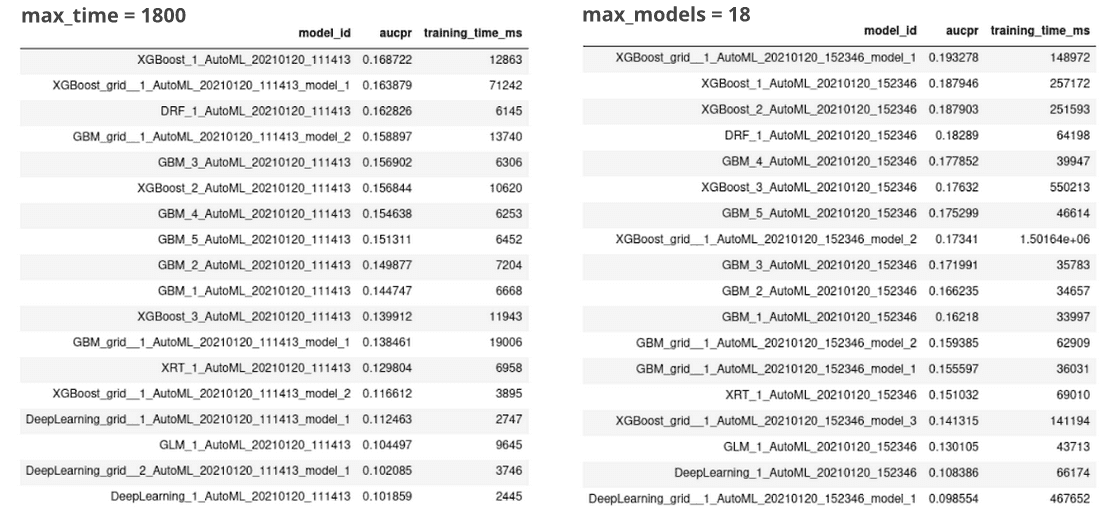
This test was performed on the Fraud Detection in Electricity and Gas Consumption dataset, described in the first article, and run on a laptop with 8 cores and 32 GB RAM. First, we launched H2O AutoML for 30 min (max_runtime_sec = 1800). 18 models were built. Then, we launched the H2O AutoML with max_models = 18, without the additional time constraint. The training took 7.5 hours. If we compare the leaderboards, we see that the most/least successful algorithms stay the same, but the exact model ranking changes. Without the time constraint, AUCPR improved. Also, the majority of the training times are much longer.
Depending on the phase of the project, one or the other parameter might be preferred. For example, when we received a new dataset, we run H2O AutoML for 10 minutes to see how many models we get, how far are we from the performance of the reference model, which algorithms are performing badly and not worth optimizing, etc. This gave us the initial idea of how much work we need to invest in the optimization. On the other hand, when the project was progressing, we wanted to be sure that the models are well-trained with known stopping points. We preferred to define the max number of trained models and let it run as long as needed.
The difference between the H2O AutoML grid search and the ‘classical’ grid search
There are two different approaches to grid search in H2O:
- grid search as a part of H2O AutoML: during the AutoML modeling phase, a limited grid search is executed. The list of hyperparameters and their values can be found here. In version 3.30.0.3 of H2O, only XGBoost, GBM, and Deep Neural Nets are optimized through automatic grid search. It’s worth noting that also some H2O AutoML parameters themselves are identified as hyperparameters (e.g.
max_runtime_sec,balance_classes), while some are not (e.g.max_models,nfolds). - classical grid search: in this option, we can change virtually all the parameters of a model. If we look at the model definition in Flow UI, we will see that the parameters are grouped as basic, advanced, and expert, which helps us decide which are the most important to start with (from basic to expert). As a strategy, we can choose between:
- cartesian: goes through all the combinations of parameters, which soon leads to the explosion of the number of models.
- random: chooses some combination of parameters randomly. In open-source H2O, there is no informed search method available to improve the results and speed up the process.
We were disappointed about the lack of Bayesian optimization, which select next hyperparameter values to be tested, based on the previous results. Alternatively, we opted for a strategy where we let AutoML build 30+ models to be sure to include the automatic grid search. We took the best model, extracted its parameters, and defined the classical grid search around those parameters to achieve some additional improvement. However, this remains local optimization, and we cannot be sure to have the best model.
Another minor inconvenience from the user’s perspective is that the classical grid search does not print out the progress during modeling (we tried to change the setting, but we were not successful), so we cannot be sure if it’s working or it broke down during the process. A workaround is to open the Flow UI, execute getGrids, and follow the progress from there.
Optimization (stopping) metrics
We can choose among many statistical optimization metrics. Unfortunately, the support for a user-defined metric is very limited. We can use it only with DRF and GBM, and only in Python client. Here is the documentation with examples.
This was one of the major downsides for us. All the models needed to be re-evaluated after training with two business metrics. This increased the processing time, but most importantly, it optimized the models on the statistical metrics that do not completely correlate with the business ones. Consequently, the models might not learn the correct representation of our problem.
The benefit of stacked ensembles
H2O AutoML automatically builds two stacked ensembles: one from all the models and one from the best model of each family. They are not included in max_models count or max max_runtime_sec. The total run time will be longer than what you specify, but it only takes a couple of minutes to build them. Stacked ensembles usually perform the best, or at least very well, when the models are optimized on one of the proposed stopping metrics. But, if your true metric is a business metric, the performance on the business metric can be worse. Also, stacking adds additional complexity to interpretation.
In addition to the default stacks, you can define your own. For this, you need to train a certain number of models and stack them together with one of the metalearner algorithms (e.g.: XGB, GBM, DRF…). There are several metalearner parameters, which you can optimize. Beware, just putting together arbitrary models will not necessarily result in a stack that will outperform individual models. This requires as much testing and optimization as modeling itself.
Importing data and converting it to H2OFrame
H2O distinguishes between two different imports of files:
- upload: pushes the data from the client to the server
- import: pulls the data from the server location, specified by the client.
Depending on where is your data with respect to the server (already on the server or not), one or the other might be more appropriate.
Once the data is read, it needs to be parsed and converted to an H2OFrame. We noticed the following:
- no possibility to define the schema to be used on the import, but once the data is imported, you can change the column types.
- with one of the datasets, extra rows appeared after converting pandas data frame to H2OFrame. The bug has been reported before (duplication of lines). It seems to be very specific, and not to be resolved yet. In our case, removing duplicated rows only removed a small number of unwanted rows. When we removed the columns not needed for the modeling, the problem disappeared. We suggest verifying the shape of the data frame before and after the conversion to the H2OFrame.
Multiple connections to the same session
Another useful functionality was the possibility of connecting to the same session from different notebooks and access the objects in memory. For example, during the training, you can access and use a model as soon as it was finished. In our case, it meant that we didn’t need to wait for hours for the whole training to be completed before computing the business metrics. We were able to do it with a much shorter delay from a parallel session. All you need to do is to name the objects at creation in your primary session. For example, when you run the H2O AutoML function, you define project_name or destination_frame when you import data. Then, you connect to the same session from another notebook (h2o.connect(ip='xxx', port='yyy')). You can access them by using the names of the objects you defined in the first notebook. For example, you can run h2o.automl.get_automl(project_name).leaderboard to access the leaderboard of a specified project, even if the training is not finished yet.
Theoretically, this opens the possibility of multiple users sharing the same session. This sounds appealing especially when working with large datasets. The data could be loaded only once, and all the users could access it. In practice, it turned out that accidental modifications or re-uploads of the shared objects happen too often to be of use.
Conclusion
During the first part of the mission, we had four weeks to grasp H2O and build the best model we could. With the API in R and Python, we found the entry barrier very low.
Using AutoML combined with individual modeling algorithms within the same framework, increased the productivity in the starting phases. We were able to test many parameters of many models with minimal effort. H2O AutoML removes the need for repeatable boilerplate code, like accessing the performance of each model and making a leaderboard manually. It significantly shortens coding time, so data scientists can focus on the business side of the problem.
A great plus is the extended visualization and the model performance evaluation in Flow UI that can be used together with the API. The possibility to interact with the session through different notebooks can further parallelize the work.
But we also saw some limitations. Most notable for us were the lack of optimization for a random search and very limited support for user-defined metrics. Nevertheless, we managed to build a model with similar performance as the reference model, in a much shorter time. We also devised a step-by-step protocol to help you leverage the described functionalities as fast as possible. But let’s keep that for the following article.
Acknowledgements
The collaborators who contributed to this work are:
- Somsakun Maneerat, EDF Lab, Data scientist
- Benoît Grossin, EDF Lab, Project manager
- Jérémie Mérigeault, ENEDIS, Data scientist
