


H2O en pratique: retour d'expérience d'un Data Scientist

29 sept. 2021
- Catégories
- Data Science
- Formation
- Tags
- Automation
- Cloud
- H2O
- Machine Learning
- MLOps
- On-premises
- Open source
- Python [plus][moins]
Ne ratez pas nos articles sur l'open source, le big data et les systèmes distribués, fréquence faible d’un email tous les deux mois.
Les plates-formes d’apprentissage automatique (AutoML) gagnent en popularité et deviennent un outil puissant à disposition des data scientists. Il y a quelques mois, j’ai présenté H2O, une plate-forme open source d’AutoML, accompagné d’un tutoriel. Récemment, j’ai eu une excellente occasion de le tester en pratique. Je travaillais avec l’un de nos clients, EDF Lab, avec la participation d’ENEDIS. Les deux sociétés sont des acteurs majeurs du marché français de l’électricité, ENEDIS étant le mainteneur du réseau et EDF le principal fournisseur d’électricité. Le cas d’usage sélectionné couvrait la maintenance préventive d’un réseau électrique souterrain basse tension. Plus précisément, la question était de savoir comment détecter les segments de câbles (lignes d’alimentation) à remplacer pour éviter les coupures de courant. Ce cas d’usage a été largement étudiée et publiée auparavant.
Plusieurs modèles ont été développés au préalable. Par conséquent, le but de la mission n’était pas la modélisation elle-même mais plutôt d’estimer la valeur ajoutée d’une solution d’AutoML. Réduira-t-elle le temps de modélisation et/ou produira-t-elle de meilleurs modèles ? Nous avons commencé par la comparaison des frameworks existants. Une excellente référence peut être trouvée ici. Le critère de sélection le plus restrictif est probablement la nature open source du framework. À savoir, de nombreux frameworks AutoML sont propriétaires. Notre regard s’est concentré sur H2O. Notre tâche était de comprendre son fonctionnement, sa barrière à l’entrée, ses performances sur des données du monde réel et de comparer la qualité du modèle construit avec AutoML avec les modèles de référence internes.
Nous aimerions partager notre expérience, en soulignant les fonctionnalités qui ont retenu notre intérêt et celles qui nous manquaient avec H2O. Gardez à l’esprit que nous parlons de la version open source. Driverless AI, la solution édité par H20.ai, peut se comporter différemment et comprend de nombreuses fonctionnalités additionnelles.
Puisque nous avons couvert les fondamentaux d’H20 précédemment, nous allons plonger directement dans des sujets spécifiques cette fois :
- Comment fonctionne la fonction H2O AutoML :
- Comment choisit-il les algorithmes à tester ?
- Quelle différence cela fait-il si nous définissons
max_modelsoumax_runtime_secs? - Parcourt-il la liste prédéfinie d’algorithmes toujours dans le même ordre ?
- Différence entre la recherche en grille (grid search en anglais) sur H2O AutoML et une recherche en grille traditionnelle.
- Métriques d’optimisation (arrêt).
- L’avantage des ensembles superposés.
- Import des données et convertion vers H2OFrame.
- Plusieurs connexions à une même session.
Jeu de données et environnement
H2O en déclinaison open source ne prend en charge que les fonctionnalités de base en terme de préparation des données et n’automatise pas le feature engineering. Ainsi, nous utilisions un jeu de données déjà préparé, composé des données de 2018 et 2019. Il contenait les descripteurs des propriétés du réseau et les informations sur les incidents pour chaque émetteur. Les données de test et d’entraînement contenaient un peu plus d’un million de lignes avec 434 colonnes chacune. Les données ont été importées à partir d’un fichier au format Parquet. Elles étaient nettoyées et prêtes à l’emploi. La tâche était la classification d’un ensemble de données fortement déséquilibré (< 0,5% de la classe 1). AUCPR a été utilisé comme mesure d’optimisation pendant l’entraînement. Pour l’évaluation finale du modèle, deux mesures métiers ont été calculées, représentant toutes deux le nombre de défaillances sur deux différentes longueurs cumulatives d’émetteur à remplacer. Une validation croisée 5 fois a été utilisée pour valider les modèles.
- H2O_cluster_version : 3.30.0.3\
- H2O_cluster_total_nodes : 10\
- H2O_cluster_free_memory : 88.9 Gb\
- H2O_cluster_allowed_cores : 50\
- H2O_API_Extensions : XGBoost, Algos, Amazon S3, Sparkling Water REST API Extensions, AutoML, Core V3, TargetEncoder, Core V4\
- Python_version : 3.6.10 final
Results
Which models will the H2OAutoML function test ?
H2O AutoML offree une liste de modèles prédéfinies, qui seront automatiquement construits pendant l’entraînement. Des grilles d’hyperparamètres pour la recherche en grille sont également prédéfinies. La documentation indique :
The current version of AutoML trains and cross-validates the following algorithms (in the following order) :
- three pre-specified XGBoost GBM (Gradient Boosting Machine) models
- a fixed grid of GLMs
- a default Random Forest (DRF)
- five pre-specified H2O GBMs
- a near-default Deep Neural Net
- an Extremely Randomized Forest (XRT)
- a random grid of XGBoost GBMs
- a random grid of H2O GBMs
- a random grid of Deep Neural Nets.
In some cases, there will not be enough time to complete all the algorithms, so some may be missing from the leaderboard. AutoML then trains two Stacked Ensemble models.
List of the parameters for tuning
Random Forest and Extremely Randomized Trees are not grid searched (in the current version of AutoML), so they are not included in the list below.”
Cette configuration est très utile dans les phases initiales de modélisation. Nous pouvons tester de nombreux modèles différents avec un seul appel de fonction. Nous n’avons pas besoin de passer du temps à décider quel modèle sera le plus adapté au problème et ce qu’il faut inclure dans la recherche en grille. Au lieu de cela, nous pouvons exécuter l’ensemble des modèles par défaut et approfondir en fonction des résultats.
Si nous ne sommes pas intéressés par tous les algorithmes ou si nous souhaitons raccourcir le temps de calcul (puisque l’exécution complète peut être longue), nous pouvons spécifier ceux que nous voulons inclure/exclure avec les paramètres include_algos et exclude_algos. Par exemple, après la première exécution, nous avons vu que les réseaux de neurones profonds (Deep Neural Nets) étaient les moins performants.
De plus, l’explicabilité du modèle pourrait être importante pour le projet. Nous avons donc exclu les réseaux de neurones profonds de toutes les entraînements suivants. D’autre part, en testant les paramètres H2O AutoML (comme balance_classes, nfolds, etc.), nous avons remarqué que XGBoost (XGB) fonctionnait toujours bien mieux que les autres algorithmes. Finalement, nous n’avons inclus que XGB, pour pouvoir exploiter au maximum la recherche en grille dans un temps donné.
H2O AutoML parcourt-il la liste des algorithmes toujours dans le même ordre ?
Oui. Si vous regardez la liste, vous remarquerez qu’au début, plusieurs modèles avec des paramètres fixes sont entraînés. La recherche en grille d’AutoML est placée dans la seconde moitié de la liste. Étant donné que la recherche en grille peut trouver de meilleurs paramètres que ceux par défaut, nous devons nous assurer de donner suffisamment de temps ou un nombre suffisant de modèles à AutoML. Comme ça, il terminera les modèles par défaut et continuera avec la recherche en grille. Voici plusieurs façons d’y parvenir :
- temps d’exécution suffisamment long
- construire un nombre suffisant de modèles
- sélectionner un petit nombre d’algorithmes à tester
- définir le plan de modélisation, où nous pouvons spécifier quels modèles de la liste doivent être construits. Cependant, nous devons encore laisser suffisamment de temps et/ou un nombre suffisant de modèles à AutoML pour parcourir l’ensemble du plan. Sinon, il ne terminera pas tout.
Quelle différence cela fait-il si je définis max_models ou max_runtime_secs ?
Pour définir quand l’entraînement se terminera, nous définissons soit le nombre maximal de modèles à construire (max_models) soit la durée maximale de l’entraînement (max_runtime_secs). Si les deux propriétés sont définies, l’entraînement s’arrête une fois la première condition satisfaite.
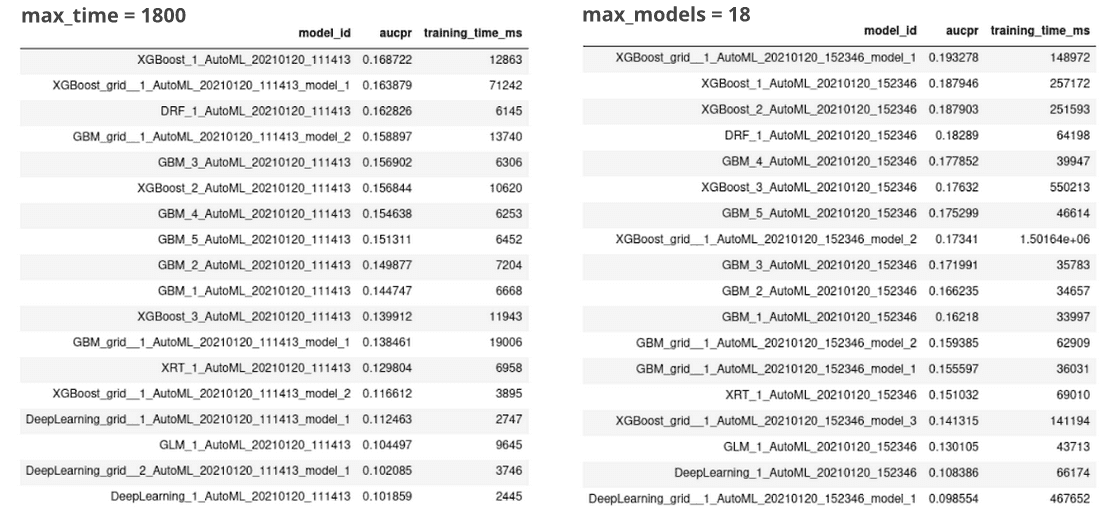
Ce test a été effectué sur le jeu de données de détection de fraude dans la consommation d’électricité et de gaz, décrit dans le premier article, et exécuté sur un ordinateur portable avec 8 cœurs et 32 Go de RAM. Tout d’abord, nous avons lancé H2O AutoML pendant 30 min (max_runtime_sec = 1800). 18 modèles ont été construits. Ensuite, nous avons lancé le H2O AutoML avec max_models = 18, sans la contrainte de temps supplémentaire. L’entraînement a duré 7,5 heures. Si nous comparons les classements, nous constatons que les algorithmes les plus/moins réussis restent les mêmes, mais le classement exact du modèle change. Sans la contrainte de temps, l’AUCPR s’est améliorée. De plus, la majorité des temps d’entraînemnet sont beaucoup plus longs.
Selon la phase du projet, l’un ou l’autre paramètre peut être préféré. Par exemple, lorsque nous recevons un nouvel ensemble de données, nous exécutons H2O AutoML pendant 10 minutes pour voir combien de modèles nous obtenons, à quelle distance sommes-nous des performances du modèle de référence, quels algorithmes fonctionnent mal et ne valent pas la peine d’être optimisés, etc. Cela nous a donné une première idée de la quantité de travail à investir dans l’optimisation. D’autre part, au fur et à mesure que le projet avançait, nous voulions être sûrs que les modèles soient bien entraînés avec des points d’arrêt connus. Nous avons préféré définir le nombre maximum de modèles entraînés et le laisser fonctionner aussi longtemps que nécessaire.
La différence entre la recherche en grille sur H2O AutoML et une recherche en grille traditionnelle.
Il existe deux approches différentes pour la recherche en grille dans H2O :
- la recherche en grille dans le cadre de H2O AutoML : durant la phase de modélisation d’AutoML, une recherche en grille réduite est exécutée. La liste des hyperparamètres et leurs valeurs peuvent être trouvées ici. Dans la version 3.30.0.3 de H2O, seuls XGBoost, GBM et Deep Neural Nets sont optimisés via la recherche en grille automatisée. Il convient de noter que certains paramètres H2O AutoML eux-mêmes sont identifiés comme des hyperparamètres (par exemple
max_runtime_secetbalance_classes), tandis que d’autres ne le sont pas (par exemplemax_modelsetnfolds). - la recherche en grille classique : avec cette option, on peut changer pratiquement tous les paramètres d’un modèle. Si nous examinons la définition du modèle dans Flow UI, nous verrons que les paramètres sont regroupés en paramètres de base, avancés et experts, ce qui nous aide à décider lesquels sont les plus importants pour commencer (de base à expert). Comme stratégie, nous pouvons choisir entre :
- cartesian : passe par toutes les combinaisons de paramètres, ce qui conduit rapidement à l’explosion du nombre de modèles.
- random : choisit une combinaison de paramètres au hasard. Dans la version open source d’H2O, il n’y a pas de méthode de recherche informée disponible pour améliorer les résultats et accélérer le processus.
Nous avons été déçus par le manque d’optimisation bayésienne, qui sélectionne les prochaines valeurs d’hyperparamètres à tester, sur la base des résultats précédents. Alternativement, nous avons opté pour une stratégie dans laquelle nous avons laissé AutoML créer plus de 30 modèles pour être sûr d’inclure la recherche de grille automatique. Nous avons pris le meilleur modèle, extrait ses paramètres et défini la recherche de grille classique autour de ces paramètres pour obtenir des améliorations supplémentaires. Cependant, cela reste une optimisation locale, et nous ne pouvons pas être sûrs d’avoir le meilleur modèle.
Un autre inconvénient mineur du point de vue de l’utilisateur est que la recherche en grille classique n’affiche pas la progression pendant la modélisation (nous avons essayé de modifier le paramètre, mais nous n’avons pas réussi), nous ne pouvons donc pas être sûrs que cela fonctionne ou qu’il est tombé en panne pendant le traitement. Une solution de contournement consiste à ouvrir l’interface utilisateur de Flow, à exécuter getGrids et à suivre la progression à partir de là.
Métriques d’optimisation (arrêt)
Nous pouvons choisir parmi de nombreuses métriques d’optimisation statistique. Malheureusement, la prise en charge d’une métrique définie par l’utilisateur est très limitée. Nous ne pouvons l’utiliser qu’avec DRF et GBM, et uniquement dans le client Python. Voici la documentation avec des exemples.
C’était l’un des principaux inconvénients pour nous. Tous les modèles devaient être réévalués après l’entraînemnet de deux métriques métier. Cela a augmenté le temps de traitement, mais surtout, cela a optimisé les modèles sur les métriques statistiques qui ne sont pas complètement corrélées avec celles de l’entreprise. Par conséquent, les modèles pourraient ne pas apprendre la représentation correcte de notre problème.
L’avantage des ensembles superposés
H2O AutoML crée automatiquement deux ensembles superposés : un à partir de tous les modèles et un à partir du meilleur modèle de chaque famille. Ils ne sont ni inclus dans max_models count ni dans max max_runtime_sec. Le temps d’exécution total sera plus long que ce que vous spécifiez, mais cela ne prend que quelques minutes pour les créer. Les ensembles superposés fonctionnent généralement mieux, ou du moins très bien, lorsque les modèles sont optimisés sur l’une des métriques d’arrêt proposées. Mais, si votre véritable métrique est une métrique métier, les performances de celle-ci peuvent être pires. En outre, la superposition ajoute une complexité supplémentaire à l’interprétation.
En plus des superpositions par défaut, vous pouvez définir les vôtres. Pour cela, vous devez entraîner un certain nombre de modèles et les superposer avec l’un des algorithmes de metalearner (ex : XGB, GBM, DRF…). Il existe plusieurs paramètres de metalearner, que vous pouvez optimiser. Attention, le simple fait de rassembler des modèles arbitraires n’entraînera pas nécessairement une superposition qui surpassera les modèles individuels. Cela nécessite autant de tests et d’optimisation que la modélisation elle-même.
Import des données et convertion vers H2OFrame
H2O distingue deux importations de fichiers différentes :
- upload : pousse les données du client vers le serveur.
- import : extrait les données de l’emplacement du serveur, spécifié par le client.
Selon l’endroit où se trouvent vos données par rapport au serveur (déjà sur le serveur ou non), l’un ou l’autre peut être plus approprié.
Une fois les données lues, elles doivent être analysées et converties en H2OFrame. Nous avons remarqué ce qui suit :
- pas de possibilité de définir le schéma à utiliser lors de l’import, mais une fois les données importées, vous pouvez changer les types de colonnes.
- avec l’un des jeux de données, des lignes supplémentaires sont apparues après la conversion de data frame pandas vers H2OFrame. Le bug a déjà été signalé (duplication de lignes). Cela semble être très précis et ne pas encore être résolu. Dans notre cas, la suppression des lignes dupliquées n’a supprimé qu’un petit nombre de lignes indésirables. Lorsque nous avons supprimé les colonnes inutiles pour la modélisation, le problème a disparu. Nous vous suggérons de vérifier la forme du data frame avant et après la conversion en H2OFrame.
Connexions multiples à une même session
Une autre fonctionnalité utile était la possibilité de se connecter à la même session à partir de différents ordinateurs portables et d’accéder aux objets en mémoire. Par exemple, pendant l’entraînement, vous pouvez accéder et utiliser un modèle dès qu’il est terminé. Dans notre cas, cela signifiait que nous n’avions pas besoin d’attendre des heures pour que tout l’entraînement soit terminé avant de calculer les métriques métier. Nous avons pu le faire sous un délai beaucoup plus court comparativement à une session parallèle. Tout ce que vous avez à faire est de nommer les objets lors de la création dans votre session principale. Par exemple, lorsque vous exécutez la fonction H2O AutoML, vous définissez project_name ou destination_frame lorsque vous importez des données. Ensuite, vous vous connectez à la même session depuis un autre notebook (h2o.connect(ip='xxx', port='yyy')). Vous pouvez y accéder en utilisant les noms des objets que vous avez définis dans le premier notebook. Par exemple, vous pouvez exécuter h2o.automl.get_automl(project_name).leaderboard pour accéder au classement d’un projet spécifié, même si l’entrainement n’est pas encore terminé.
Théoriquement, cela ouvre la possibilité pour plusieurs utilisateurs de partager la même session. Cela semble attrayant, en particulier lorsque vous travaillez avec de grands ensembles de données. Les données sont chargées qu’une seule fois et tous les utilisateurs pouvent y accéder. En pratique, il s’est avéré que les modifications accidentelles ou les re-uploads des objets partagés arrivent trop souvent pour être utiles.
Conclusion
Durant la première partie de la mission, nous avons eu quatre semaines pour appréhender H2O et construire le meilleur modèle possible. Avec l’API en R et Python, nous avons trouvé la barrière à l’entrée très faible.
L’utilisation d’AutoML combinée à des algorithmes de modélisation individuels dans le même framework a augmenté la productivité dans les phases de démarrage. Nous avons pu tester les nombreux paramètres de nombreux modèles avec un minimum d’effort. H2O AutoML supprime le besoin d’un code passe-partout à répétition, comme accéder aux performances de chaque modèle et créer un classement manuellement. Cela réduit considérablement le temps de codage, afin que les data scientist puissent se concentrer sur les problématiques métier.
Un grand avantage est la visualisation avancée et l’évaluation des performances du modèle dans Flow UI qui peuvent être utilisées avec l’API. La possibilité d’interagir avec la session via différents notebooks permet de paralléliser davantage le travail.
Mais nous avons également vu certaines limites. Le plus notable pour nous était le manque d’optimisation pour une recherche aléatoire et une prise en charge très limitée des métriques définies par l’utilisateur. Néanmoins, nous avons réussi à construire un modèle avec des performances similaires au modèle de référence, dans un temps beaucoup plus court. Nous avons également conçu un protocole étape par étape pour vous aider à tirer le meilleur parti des fonctionnalités décrites le plus rapidement possible. Mais gardons cela pour l’article suivant.
Remerciements
Les collaborateurs qui ont contribué à ce travail sont :
- Somsakun Maneerat, EDF Lab, Data scientist
- Benoît Grossin, EDF Lab, Project manager
- Jérémie Mérigeault, ENEDIS, Data scientist
